Our new paper has just been accepted for presentation at CLEF 2019 in September.
Classification and Event Identification Using Word Embedding
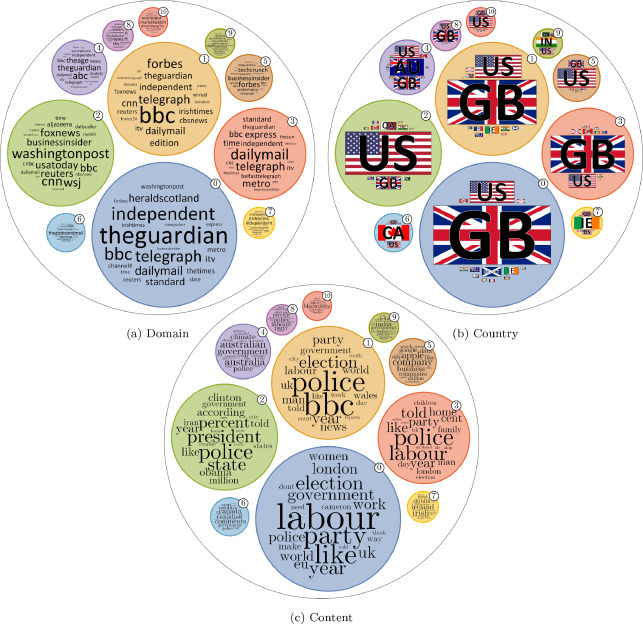
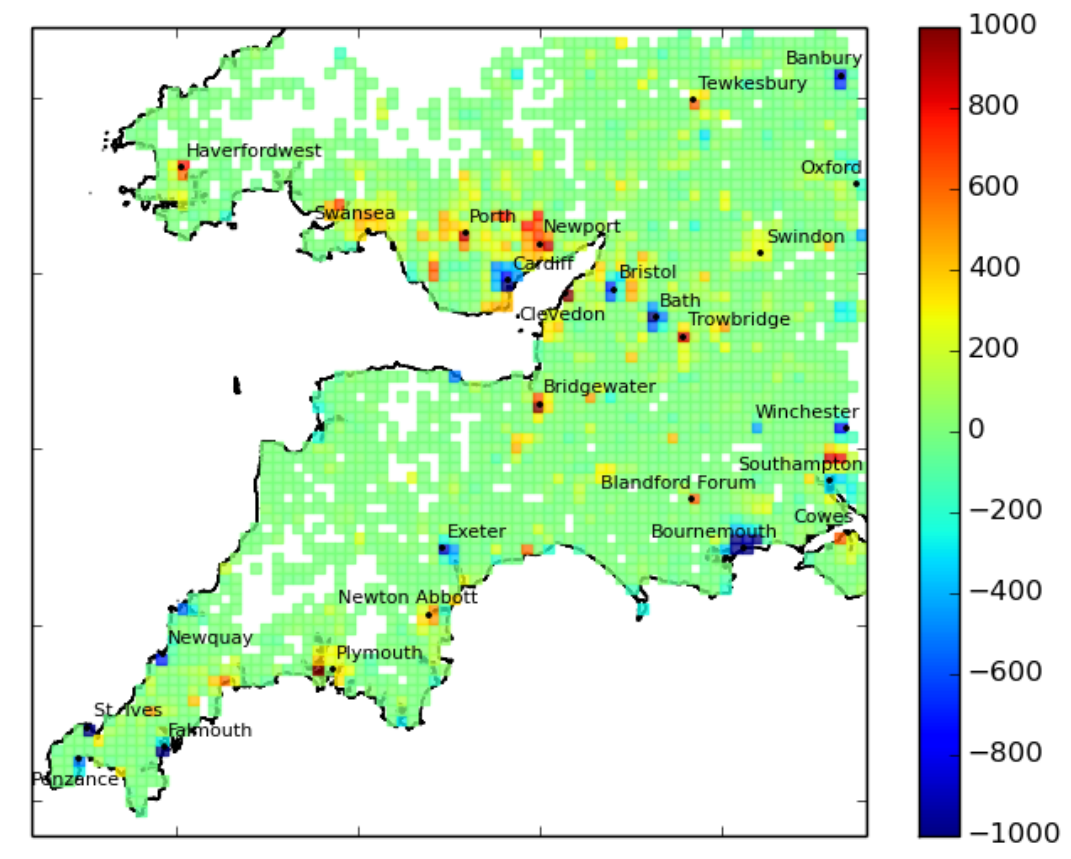
This paper presents our contribution to the CLEF 2019 ProtestNews Track, which aims to classify and identify protest events in English-language news from India and China. We used traditional classification models, namely, support vector machines and XGBoost classifiers, combined with various word embedding approaches. Multiple models were tested for experimental purposes, in addition to the two models evaluated within the official campaign. Results show promising performance, especially in terms of precision on both document and sentence classification tasks.
Come and talk to us if you would like to know more.